
Verification Code Recognition With Tesseract OCR
08 Dec 2019 | PythonOptical character recognition or optical character reader(OCR) is very popular today. OCR is the electrical or mechanical conversion of images of typed, handwritten or printed text into machine_encoded text. And OCR is the field of pattern recognition, artificial intelligence, and computer vision.
Tesseract is an optical character recognition engine, it’s free software. and the development has been sponsored by google by 2006. more information can be found in tesseract ocr.
The general idea of verification code recognition is:
- picture noise reduction
- recognize image verification code
I prepared a very simple verification code image
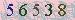
Picture Noise Reduction
Import The Image Package And Open The Image
>>> from PIL import Image
>>> im = Image.Open('56538.jpg')
Conver The Image Into Grayscale Image
>>> gray_img = im.convert('L')
>>> gray_img.show()
Open The Image In PS, Watch For The Pixel Gradation
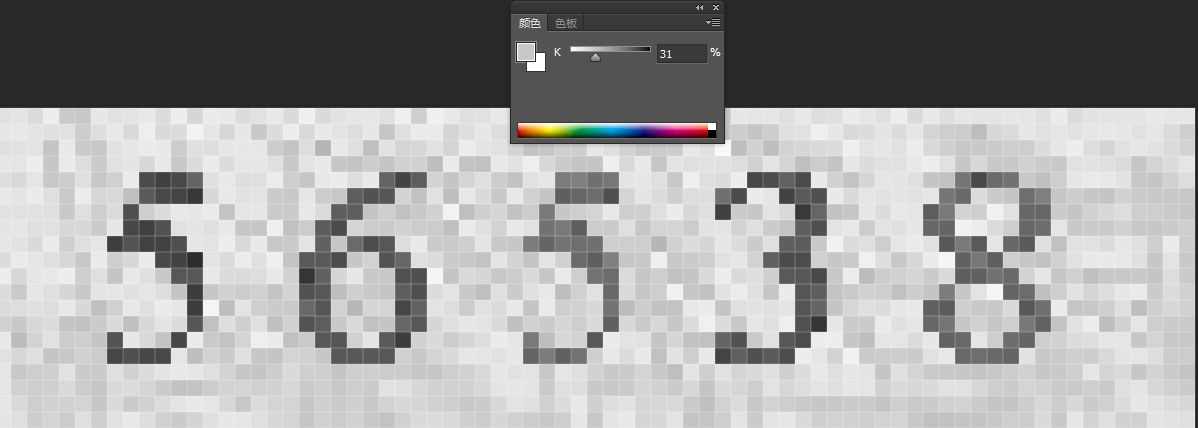
Watch for the pixel gradation value between digits and background. As you can see from the example image. The pixel gradation percentage is getting bigger from the surrounding environment to digits. It’s the white, then the light gray, then the gray, then the dark gray, then the dark.
We have to choose a pixel gradation value as a threshold that will be used in the next step. I decide to choose 35% as the target pixel gradation percentage. because it almost can difference the text and the surrounding environment. so the target threshold is: 35% * 255 = 89.25
Dithering The Image With Custom Threshold
Because this Image is simple, so we directly use binarization. set the gradation value greater than the threshold to 1, set the gradation value smaller than the threshold to 0.
generate a lookup table and map it to the image with point() function
>>> threshold = 89.25
>>> table = []
>>> for i in range(256):
... if i < threshold:
... table.append(0)
... else:
... table.append(1)
...
>>> out_img = gray_img.point(lut=table,mode='1')
>>> out_img.show()
the output picture:
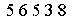
Pull The Text Out Of Image
There are a lot of OCR engines. Here I use the Tesseract Ocr Engine that development by google.
save the image with noise deducted
out_img.save('out_img.jpg')
Command Prompt
tesseract can be installed in many ways via binary package or build from source. Tesseract Ocr Github address.
my operation system is windows 10. I download the tesseract-Ocr-win64-setup-v5.0.0 version.
After installed, open the Command Prompt. input
tesseract.exe out_img.jpg stdout --psm 7
the use --psm specify the page segmentation mode. 7 represent treat the image as a single text line.
Here is the recognition result

the output is perfect, It can recognition perfectly. There is a little strange symbol in the last line. It’s an error substitution symbol. we can ignore it.
Pytesseract
Python-tesseract is a python wrapper for Google’s tesseract-OCR. Tesseract is a third party library package. the installation and other usages see pytesseract.
check the version
>>> import pytesseract
>>> print(pytesseract.get_tesseract_version())
5.0.0-alpha.20191030
After checked the version. can find more helpful information if you don’t clear on something. or input tesseract --help after installing the same version executable.
>>> from PIL import Image
>>> import pytesseract
>>> # If you don't have tesseract executable in your PATH, include the following
...
>>> pytesseract.pytesseract.tesseract_cmd = r'your tesseract executable location
>>>
>>> custom_oem_psm_config = r'--oem 3 --psm 7'
>>> image = Image.open('out_img.jpg')
>>> pytesseract.image_to_string(image, config=custom_oem_psm_config)
56538
As we write before, the --psm 7 represent treat the image as a single text line. the --oem specify the OCR Engine mode(such as Legacy or LSTM), the 3 is the default value, based on what mode is available.
The Verification Code recognize successfully.
Comments