
Everything You Need To Know Fetching Internet Resource With Python
08 Sep 2019 | PythonJust like many other languages, Python also has built-in support for internet resource access, far more than. you can fetch internet resource easily with python.
python mainly version divides into python2.x and python3.x until now. the python2.7 and python3.7 is the most stable version. python3 has been assembled the URL modules from python2, so there are some little differences in URL fetching operation between python2 and python3.
Don’t worry about complications, take patience. I will do my best to make that as clear as possible.
urllib and urllib2 in python2
python2 has two modules for fetching internet source. one of them is urllib,the another is urllib2.
urllib module
urllib provides a high-level interface for fetching data across the World Wide Web. One of the most common methods is urlopen that will return a file-like object that supports the following methods: read(), readline(), readlines(), fileno(), close(), info(), getcode().
>>> from urllib import *
>>> f = urlopen('http://www.google.com')
>>> print f.getcode()
200
>>> print f.geturl()
http://www.google.com
>>> print f.info()
Date: Sat, 07 Sep 2019 06:35:45 GMT`
Cache-Control: private, max-age=0
Content-Type: text/html; charset=ISO-8859-1
...
>>> print f.read()
<!doctype html><html itemscope="" ...
>>> f.close()
urllib2 module
urllib2 is also python2’s module, as urllib has many restrictions, check urllib restrictions. The urllib2 module defines functions and classes which help in opening URLs(mostly HTTP) in a complex world - basic and digest authentications, redirections, cookies and more.
urllib2 use an OpenerDirector instance to manage handlers that can be either instance of BaseHandler or subclass of BaseHandler. the default OpenerDirector will contain the following classes(except chains explicitly them or extends from them by urllib2.build_opener([handler, ...])). them are ProxyHandler (if proxy settings are detected), UnknownHandler, HTTPHandler, HTTPDefaultErrorHandler, HTTPRedirectHandler, FTPHandler, FileHandler, HTTPErrorProcessor.
The bellow is a simple HTTP request case with urllib2.
>>> import urllib2
>>> f = urllib2.urlopen('http://www.google.com')
>>> print f.read()
<!doctype html><html itemscope="" ...
>>> f.close()
The urlopen accepts a url parameter which can be either a string or a Request object. when we pass a string into, it will create a default Request object. bellow I pass a Request object instead.
>>> import urllib2
>>> req = urllib2.Request('http://www.google.com')
>>> print req.get_method()
GET
>>> f = urllib2.urlopen(req)
>>> print f.read()
<!doctype html><html itemscope="" ...
>>> f.close()
Request object has a lot of public interfaces. programmer can add request headers by Request.add_header(key, val) , set proxy info by Request.set_proxy(host, type), get current method of request by Request.get_method(). urllib2 official document demonstrate it clearly.
urllib in python3
The urllib module in python2 has been split into parts and renamed in python3 to urllib.request, urllib.parse, and urllib.error. Also note that the urllib.request.urlopen() function in python3 is equivalent to urllib2.urlopen() , and urllib.urlopen() has been removed.
Also, the urllib2 module in python2 has been split into parts and renamed in python3 to urllib.request, urllib.error.
The python3 has been assembled from urllib and urllib2 of python2. and the urllib in python3 is no longer a module, it’s a package instead. the urllib is a package which collects several modules for working with URLs:
urllib.requestfor opening and reading URLsurllib.errorcontaining the exceptions raised byurllib.requesturllib.parsefor parsing URLsurllib.robotparserfor parsing robots.txt files
urllib.request module
The urllib.request module assembled the opening and reading parts of the module of the urllib and urllib2 of python2. it’s a lot of futures are same with urllib2 of python2. it also uses OpenerDirector to manage Handlers which can a BaseHandler or a subclass of BaseHandler which deals with corresponding tasks.
The urllib.request.urlopen() can accept a URL string or a Request instance.
>>> import urllib.request
>>> with urllib.request.urlopen('http://www.google.com') as f:
... print(f.read())
b'<!DOCTYPE html PUBLIC "-//W3C//D.....
the urllib.request.urlopen() always returns a file-like object that has methods,such as getcode(),geturl(),info().
The urllib.request.Request class is an abstraction of URL requests. the prototype is:
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
the url should be a string containing a valid Uniform Resource Locators. the method can be POST, GET, PUT, etc…
For an HTTP POST request method, data should be a buffer in the standard application/x-www-form-urlencoded format. The urllib.parse.urlencode() function can take a mapping or sequence of 2-tuples and return that format string.
the headers should be a directory, it is the request header when fetching internet source. the programmer also can be allowed to add cookies into.
the Request object has a method called set_proxy(host,type), which prepare the request by connecting to a proxy server. Programmers can use it like:
import urllib.request
req = urllib.request.Request(url = 'http://www.httpbin.org/ip')
#req.set_proxy('ip:port','scheme')
#example:
req.set_proxy('183.128.223.120:8118','http')
f = urllib.request.urlopen(req)
data = f.read().decode('utf8')
print(data)
if you are in win7 environment, then make sure your automatically detect settings at LAN setting dialog have been clicked on.
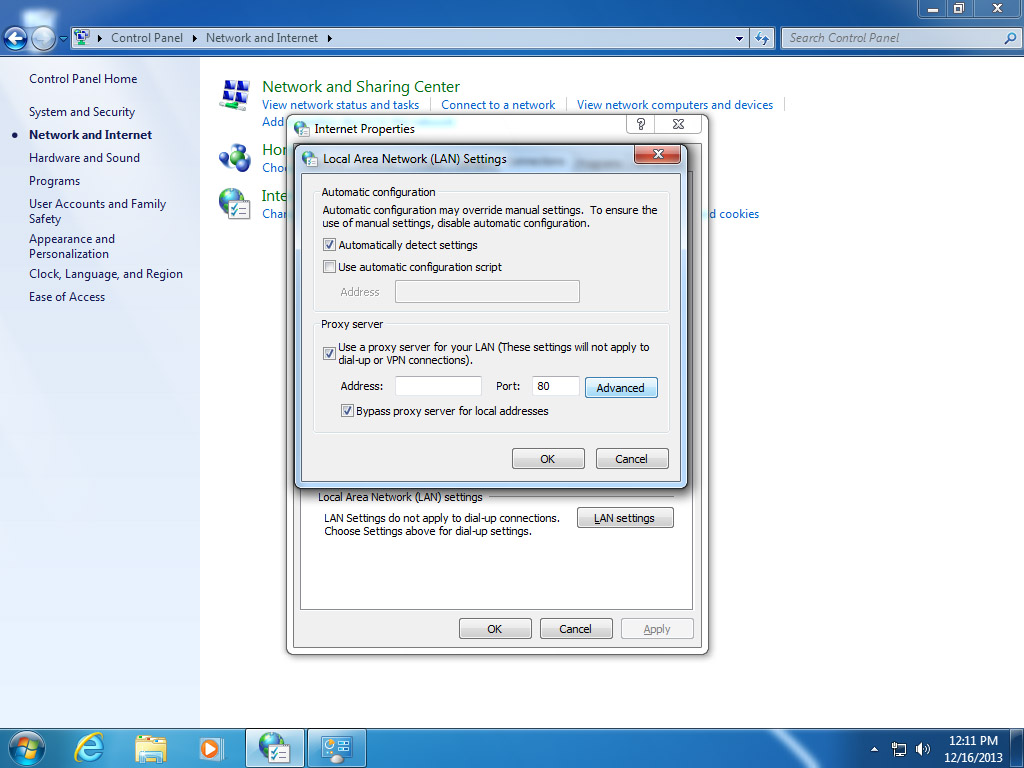
however, if you don’t want to change your computer environment, then maybe you can register a new ProxyHandler to the default OpenerDirector, and disable the default proxy settings.
import urllib.request
# disable proxy by passing an empty
proxy_handler = urllib.request.ProxyHandler({})
#alertnatively you could set a proxy for http with
#proxy_handler = urllib.request.ProxyHandler({'http': 'http://ip:port/'})
#example
proxy_handler = urllib.request.ProxyHandler({'http': 'http://183.128.223.120:8118/'})
opener = urllib.request.build_opener(proxy_handler)
url = 'http://www.httpbin.org/ip'
# open the website with the opener
f = opener.open(url)
print(f.read().decode('utf8'))
the next is a simple GET example
>>> req = urllib.request.Request(url = 'http://www.google.com',method = 'GET')
>>> f = urllib.request.urlopen(req)
>>> print(f.read())
b'<!doctype html><html itemsco...
>>> f.close()
urllib.error module
The urllib.error module defines exception classes for exceptions raised by urllib.request.
import urllib.request
import urllib.error
req = urllib.request.Request('http://locahost:8080')
f = ''
try:
f = urllib.request.urlopen(req)
except urllib.error.URLError as err:
print(err.reason)
else:
f.close()
urllib.parse module
the urllib.parse defines a standard interface to break Uniform Resource Locator up to components, to combine the components to a URL string, to convert a “Relative URL” to absolute URL given a “base URL”, to mapping a dictionary or sequence of 2-tuples to a valid POST data format.
one of the most common methods used is urllib.parse.urlencode, which will return a percent-encoded ASCII text string, which used in POST request. the result string is serials of key=value pairs separated by & notation, which follows the standard format of application/x-www-form-urlencoded.
next is a simple POST case.
import urllib.request
import urllib.error
import urllib.parse
#contruct Request with url and method
req = urllib.request.Request(url = 'http://locahost',method="POST")
f = ''
try:
#the data that needs to send
data = {"name":"Gorge",
"age":12,
"carrer":"truck driver"};
#the encoded str, it format is key1=value1&key2=value2
param = urllib.parse.urlencode(data)
#convert to bytes
bparam = param.encode("utf-8")
#request
f = urllib.request.urlopen(url = req,data = bparam)
except urllib.error.URLError as err:
print(err.reason)
else:
f.close()
urllib.robotparser module
urllib.robotparser, which used to manage Uniform Resource Locator of WWW Robots (also called wanderers or spiders) visits. this is outside of the scope of this document.
Conclusion
congratulations, you have been learned the part of internet fetching resource. I hope I wrote it clear.
let me recap. In python2, which have two modules use for fetching internet resource, they are urllib and urllib2. the urllib2 is the enhanced edition of the urllib, the mechanism of urllib2 use an OpenerDirector to manage serial of Handlers.
python3 assembled the future of urllib and urllib2 of python2 into urllib.request, urllib.error, urllib.parse. Be careful that the urllib.request.urlopen corresponding of urllib2.urlopen().
Alright! we have arrived at the bottom of this document. I hope you absorb this well. The Mid-Autumn festive is coming, Have a good Mid-Autumn Festive. bye buds!
Comments